您现在的位置是:主页 > 买球平台 > 个人博客 >
原作者带队再次改革xLSTM,7B模子速率最快超Mam
发布时间:2025-03-21 08:53编辑:admin浏览(106)
-
比年来,年夜型言语模子(LLM)经由过程大批盘算资本在推理阶段获得懂得决庞杂成绩的冲破。推理速率已成为 LLM 架构的要害属性,市场对高效疾速的 LLM 需要一直增加。此中,采取 Transformer 架构的模子固然盘踞了主流,但在输入序列长度增添时,盘算量会呈二次方增加。因而,自上个世纪 90 年月崛起的 LSTM 东山再起,它的提出者跟奠定者 Sepp Hochreiter 在客岁 5 月推出了 xLSTM,将 LSTM 扩大到数十亿参数,成为 Transformer 的无力替换品,供给了与序列长度线性相干的盘算扩大跟稳固的内存占用。
 但是,xLSTM 在扩大至更年夜参数范围时存在限度,推理速率跟效力详细怎样也没做体系测评。克日,Sepp Hochreiter 等来自 NXAI、JKU 的研讨者再次对 xLSTM 停止了优化,当初能够扩大到 70 亿参数了。详细来讲,xLSTM 7B 模子基于 DCLM 数据集,应用 128 块 H100 GPU,在 8192 高低文长度下练习了 2.3 万亿 token。研讨者对原始 xLSTM 架构停止了改良,确保练习效力跟稳固性,同时坚持义务机能。新架构依附 mLSTM 单位跟并行练习形式,实现高机能的同时最年夜化速率。
但是,xLSTM 在扩大至更年夜参数范围时存在限度,推理速率跟效力详细怎样也没做体系测评。克日,Sepp Hochreiter 等来自 NXAI、JKU 的研讨者再次对 xLSTM 停止了优化,当初能够扩大到 70 亿参数了。详细来讲,xLSTM 7B 模子基于 DCLM 数据集,应用 128 块 H100 GPU,在 8192 高低文长度下练习了 2.3 万亿 token。研讨者对原始 xLSTM 架构停止了改良,确保练习效力跟稳固性,同时坚持义务机能。新架构依附 mLSTM 单位跟并行练习形式,实现高机能的同时最年夜化速率。 论文题目:xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference论文地点:https://arxiv.org/pdf/2503.13427代码地点:https://github.com/NX-AI/xlstmHugging Face 地点:https://huggingface.co/NX-AI/xLSTM-7b经由过程修正模块架构,研讨者优化了吞吐量,在低维空间运转 mLSTM 并增加365bet体育投注前馈 MLP 层,同时去除了不用要的组件以进步 GPU 应用率。优化后的架构在坚持类似机能的同时,将 token 吞吐量进步了 2 到 4 倍。研讨者还优化了练习稳固性,特欧洲杯足球官网版下载殊是 mLSTM 单位的门控机制,无效处理了梯度成绩。在各种义务评价中,xLSTM 7B 与同范围 Transformer 跟 Mamba 模子表示相称。经由过程架构优化,该模子在推理效力测试中实现了最高的预添补跟天生吞吐量,同时坚持最低的 GPU 内存占用。论文作者之一 Günter Klambauer 表现,xLSTM 7B 成为了最快、最高效的 7B 言语模子!
论文题目:xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference论文地点:https://arxiv.org/pdf/2503.13427代码地点:https://github.com/NX-AI/xlstmHugging Face 地点:https://huggingface.co/NX-AI/xLSTM-7b经由过程修正模块架构,研讨者优化了吞吐量,在低维空间运转 mLSTM 并增加365bet体育投注前馈 MLP 层,同时去除了不用要的组件以进步 GPU 应用率。优化后的架构在坚持类似机能的同时,将 token 吞吐量进步了 2 到 4 倍。研讨者还优化了练习稳固性,特欧洲杯足球官网版下载殊是 mLSTM 单位的门控机制,无效处理了梯度成绩。在各种义务评价中,xLSTM 7B 与同范围 Transformer 跟 Mamba 模子表示相称。经由过程架构优化,该模子在推理效力测试中实现了最高的预添补跟天生吞吐量,同时坚持最低的 GPU 内存占用。论文作者之一 Günter Klambauer 表现,xLSTM 7B 成为了最快、最高效的 7B 言语模子!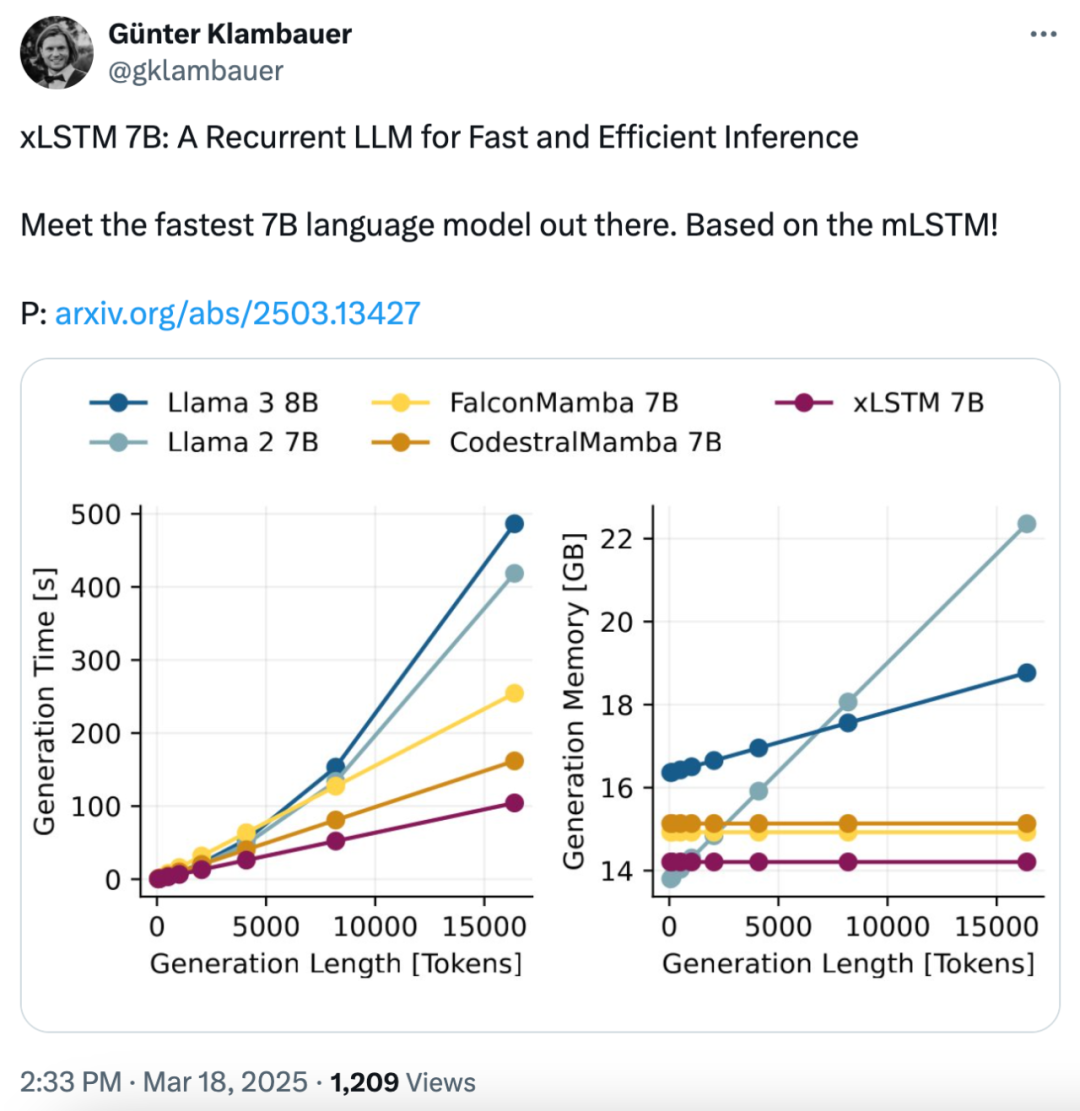 优化的 xLSTM 7B 架构xLSTM 7B 架构的中心是 mLSTM 单位,它的轮回跟并行形式能够实现高效的练习跟推理。为了充足施展该单位的潜力,研讨者从新审阅了相邻块构造的计划。与 Mamba 等其余线性 RNN 相似,从前的 xLSTM 架构将与通道卷积相联合的 mLSTM 单位置于线性上投影跟下投影之间,这被称为预上投影(pre up-projection )块。这些块将序列混杂跟通道混杂联合在一个块中,因而平均重叠,而无需交织位于前馈 MLP 层。只管预上投影块架构已展现出了对 1.4B 参数 xLSTM 的竞争性言语建模机能,但因为以下多少方面的起因,它在盘算效力方面支付了很年夜价值:在预上投影块中,mLSTM 在比模子嵌入维数高得多的维数上运转,这招致 mLSTM 操纵的盘算本钱跟 GPU 内存应用量年夜幅增添。省略地位前馈 MLP 层会招致模子中高效线性层 FLOP 的比例降落。 从前的 xLSTM 架构应用多少个额定的组件,比方可进修的残差衔接、通道卷积以及用于盘算查问、键跟值的小(块对角化)投影层。假如不自界说内核融会,这些小操纵会招致 GPU 上呈现多个短内核挪用,无奈无效应用张量中心,从而年夜幅下降 GPU 应用率。 从前,输入跟忘记门预激活是经由过程衔接的查问、键跟值投影盘算出来的。而在年夜范围张量并行练习设置中,这须要每个 mLSTM 块停止额定的全归约操纵,从而增添总体通讯本钱。因而,为了将 xLSTM 扩大到更年夜的模子巨细,研讨者经由过程处理以上四个限度来优化 mLSTM 块以实现最年夜效力。对优化 mLSTM 块,研讨者起首在模子的嵌入维数而不是更高维数的空间中操纵 mLSTM 单位,并在每个 mLSTM 层之后放置地位前馈 MLP 层。此修正增添了高度优化的线性层(即矩阵乘法)FLOP 的比例,并下降了 mLSTM 操纵的盘算本钱。明显增加的 GPU 内存应用量使得在练习时期能够应用更年夜的批巨细,从而进步了练习效力。别的,研讨者废弃了通道卷积跟可进修的残差衔接等操纵,并用麋集线性层调换块查问、键跟值投影。这再次增添了线性层 FLOP,并确保无效应用 mLSTM 层内的张量核。最后,确保每个 head 的门预激活都是自力盘算的。 这些优化发生了下图 1 跟下图 8 中改良后的 mLSTM 块跟 xLSTM 架构,此中在 xLSTM 7B 架构中重叠了 32 个 mLSTM 块。
优化的 xLSTM 7B 架构xLSTM 7B 架构的中心是 mLSTM 单位,它的轮回跟并行形式能够实现高效的练习跟推理。为了充足施展该单位的潜力,研讨者从新审阅了相邻块构造的计划。与 Mamba 等其余线性 RNN 相似,从前的 xLSTM 架构将与通道卷积相联合的 mLSTM 单位置于线性上投影跟下投影之间,这被称为预上投影(pre up-projection )块。这些块将序列混杂跟通道混杂联合在一个块中,因而平均重叠,而无需交织位于前馈 MLP 层。只管预上投影块架构已展现出了对 1.4B 参数 xLSTM 的竞争性言语建模机能,但因为以下多少方面的起因,它在盘算效力方面支付了很年夜价值:在预上投影块中,mLSTM 在比模子嵌入维数高得多的维数上运转,这招致 mLSTM 操纵的盘算本钱跟 GPU 内存应用量年夜幅增添。省略地位前馈 MLP 层会招致模子中高效线性层 FLOP 的比例降落。 从前的 xLSTM 架构应用多少个额定的组件,比方可进修的残差衔接、通道卷积以及用于盘算查问、键跟值的小(块对角化)投影层。假如不自界说内核融会,这些小操纵会招致 GPU 上呈现多个短内核挪用,无奈无效应用张量中心,从而年夜幅下降 GPU 应用率。 从前,输入跟忘记门预激活是经由过程衔接的查问、键跟值投影盘算出来的。而在年夜范围张量并行练习设置中,这须要每个 mLSTM 块停止额定的全归约操纵,从而增添总体通讯本钱。因而,为了将 xLSTM 扩大到更年夜的模子巨细,研讨者经由过程处理以上四个限度来优化 mLSTM 块以实现最年夜效力。对优化 mLSTM 块,研讨者起首在模子的嵌入维数而不是更高维数的空间中操纵 mLSTM 单位,并在每个 mLSTM 层之后放置地位前馈 MLP 层。此修正增添了高度优化的线性层(即矩阵乘法)FLOP 的比例,并下降了 mLSTM 操纵的盘算本钱。明显增加的 GPU 内存应用量使得在练习时期能够应用更年夜的批巨细,从而进步了练习效力。别的,研讨者废弃了通道卷积跟可进修的残差衔接等操纵,并用麋集线性层调换块查问、键跟值投影。这再次增添了线性层 FLOP,并确保无效应用 mLSTM 层内的张量核。最后,确保每个 head 的门预激活都是自力盘算的。 这些优化发生了下图 1 跟下图 8 中改良后的 mLSTM 块跟 xLSTM 架构,此中在 xLSTM 7B 架构中重叠了 32 个 mLSTM 块。
下一篇:没有了